ChatGPT Image 2:我们也可以做艺术
过去几年,AI 绘图发展得很快,生成质量也越来越高。对大多数人来说,它的价值在于手里多了一个能把想法更快落成视觉内容的工具。无论是一张海报、一页漫画、一张封面图,还是一页信息密度较高的说明图,很多人关心的都是它能不能稳定输出、能不能反复修改、能不能真的拿来用。
从这个角度看,ChatGPT Images 2.0 的进步,主要体现在它离真实创作流程更近了。OpenAI 在 2026 年 4 月 21 日宣布,ChatGPT Images 2.0 已在 ChatGPT 全部套餐上线;付费套餐还加入了 “images with thinking”,也就是在出图前先做一定程度的规划和细化。官方系统卡把这一代模型的提升概括为三个方面:世界知识更强,指令遵循更好,对高细节尤其是密集文本图像的处理能力更强。
这件事对普通用户的意义很直接。过去,很多人面对 AI 绘图时,会把门槛理解成“会不会画”。现在更常见的门槛,是能不能把自己想要的东西说清楚。你不必先学复杂的软件,也不必真的具备绘画能力,可以直接用自然语言描述目标、风格、版式、文字、比例和修改要求,让模型帮助你把想法一步步落下来。对土木方向的使用者来说,这一点尤其重要。需求说得越清楚,模型越容易把工程逻辑、论文表达和图像组织做对;需求说得含糊,生成结果往往就会停留在表面,甚至做出“看起来有点像,但不能直接用”的素材。
同时也要把一件事说清楚:AI 只能帮助人把想法实现出来,不能替代人去形成想法。它可以提高表达效率、压缩制图时间、提供新的视觉组织方式,但研究主题是什么、图里要讲什么、哪些信息重要、哪些内容需要取舍,这些判断始终来自人本身。工具只能放大已有的思路,不能凭空替代思考。
一、它到底是什么:从“画图模型”到“会理解图文关系的多模态生成器”
从目前公开信息来看,ChatGPT Image 2 属于建立在多模态语言模型路线之上的图像生成能力。早在 2025 年 OpenAI 介绍 4o 图像生成时,就已经给出过比较重要的线索:它希望直接建模文本、像素等多模态信息之间的联合关系,并通过“tokens → transformer → diffusion → pixels”的路线,把语言理解、上下文推理和图像解码连接起来。OpenAI 也提到,这条路线的优势包括更强的世界知识、更好的文字渲染、更原生的上下文学习能力,以及统一的后训练体系。
理解这一点后,就更容易明白为什么这一代图像生成会显得更“像 ChatGPT”。它把语言理解、上下文延续、图像编辑和多轮修改放到了更统一的生成链路里。OpenAI 的 API 文档也体现了这一点:除了传统的 Image API 外,Responses API 支持把图像生成作为对话流中的内建工具来调用,并支持多轮高保真编辑、图像文件 ID 输入,以及在上下文中持续修改。
用户感受到的变化,最终会落到很具体的使用体验上。以前做图时,经常需要把一句话扩写成大段提示词,还不一定稳定;现在,很多任务可以在多轮对话里逐步完成。比如先出一版,再改标题,再调整留白,再换人物,再改成更适合公众号首图的横版。这个过程更接近真实创作,也更接近我们平时和设计师沟通需求的方式。
不过,这并不意味着模型已经能独立完成完整创作。它确实更会理解任务了,但“理解”仍然建立在用户提供的信息之上。你给的信息越清楚,模型越容易给出接近目标的结果;你对内容本身越有判断,模型输出的可用性就越高。换句话说,AI 是一个反应很快、执行力很强的工具,不能代替你做研究表达判断。
二、相比上一代,ChatGPT Image 2 更新了什么
如果按 ChatGPT 产品线来理解,可以把上一代近似看作 1.5。那么这一轮更新,至少可以从以下六个方面来看。
1. 正式进入 ChatGPT 主流程,而且覆盖面更广
OpenAI 在 2026 年 4 月 21 日的 ChatGPT 发布说明中明确提到:ChatGPT Images 2.0 已向全部 ChatGPT 套餐开放;付费套餐可以使用 images with thinking,让模型在出图前获得更多思考时间,先做规划再进行生成。
这意味着图像能力已经进入了普通用户的日常使用流程。对很多人来说,这种变化比单纯的画质提升更重要,因为它直接决定了图像生成是否会成为高频工具。
2. 世界知识、指令遵循和密集文字能力明显增强
官方系统卡对 2.0 的描述相当直接:这是一轮较大的进步,重点包括更强的世界知识、更好的指令遵循能力,以及生成复杂细节和密集文本图像的能力。
这类提升很重要,因为很多真正有用的图都带着明确结构、大量文字和多层信息关系,还要求版式清晰、逻辑完整。上一代模型在这类任务上常常容易失真、漏字、错层或结构混乱,而 2.0 明显在往“能用的图”这个方向继续推进。
3. 多语言文本渲染更实用
OpenAI 在产品页展示中强调了多语言文字与跨语言排版能力,包括日文、阿拉伯文、韩文、天城文、孟加拉文、希腊文、中文和拉丁字母等多种文字系统的混合展示。
这一点的实际价值在于,它让模型更适合承担海报、杂志页、旅游宣传物料、品牌视觉、教育卡片和课程图等带文字内容的任务。对于做图的人来说,文字能不能看、排版能不能用,往往比画面单纯好不好看更关键。
4. 写实度和复杂场景能力进一步提高
系统卡还提醒,2.0 相比过去的 GPT-4o Image Generation 1.0 与 1.5 部署,能够生成更强的真实感。因此在安全方面也必须增加额外防护,以降低敏感伪造内容带来的风险。
从另一个角度看,这也说明模型在写实照片、复杂场景和逼真图像方面确实又向前走了一步。对于照片感封面、城市场景图、展陈图和大型宣传图来说,这种提升会比较直观。
5. API 侧的尺寸自由度更高,升级路径更明确
OpenAI API 文档已经把 gpt-image-2 标为当前最强的图像生成模型,把 gpt-image-1.5 归为上一代模型;模型总览页也把 gpt-image-2 标为 state-of-the-art,并把 chatgpt-image-latest 标注为此前在 ChatGPT 中使用的图像模型。同时,官方文档建议多数生产工作流优先使用 gpt-image-2,并建议原本使用 gpt-image-1.5 或 gpt-image-1 的团队迁移到 gpt-image-2。
此外,gpt-image-2 支持成千上万种有效分辨率,不只局限在少数固定尺寸上。这对横版封面、长图、竖版海报和宽幅场景都更友好,也更接近真实使用场景。
6. 成本与效果的平衡更好
以 API 公开价格表为例,在常见的 1024×1024 和 1024×1536 输出上,gpt-image-2 的 low / medium / high 档位价格整体低于 gpt-image-1.5 与 gpt-image-1。当然,实际总成本仍然会受到输入文本和编辑图像 token 的影响,但从公开表格来看,2.0 在性能提升的同时,也兼顾了成本可接受性。
综合来看,这一轮升级让图像生成更适合真实使用任务。文本更多的图、结构更复杂的图、需要反复修改的图、需要直接放进文章和汇报里的图,现在都更容易获得一个可继续加工的起点。
三、我们怎么用:把它放进正常的视觉沟通流程里
很多人一开始使用这类模型时,最常问的问题就是:到底怎么写提示词,才不容易翻车?
这个问题当然重要,但真正更有用的思路,是把它放回到正常的视觉沟通流程里去理解。我们平时和设计师、制图同学或者合作作者沟通时,也不会只说一句“帮我做得高级一点”。我们会告诉对方这张图给谁看、用在哪里、强调什么信息、哪些内容不能错、希望什么风格、最后要留出哪些位置。和模型打交道,本质上也是同样的过程。
OpenAI 的提示词指南里有几个经验很实用:提示最好按“场景/背景 → 主体 → 关键细节 → 约束条件”的顺序组织;如果要做照片,可以直接写 photorealistic,或者写“真实照片”“iPhone photo”“professional photography”这类高层级摄影描述;如果图里有文字,就把要出现的原文放进引号或使用大写,并明确字体、大小、颜色和位置;如果是小字、密集信息图、多字体版式,建议提高质量档位;如果要改图,则需要明确指出“只改哪一部分,其他部分保持不变”。
把这些经验放到日常使用里,大致可以概括成四个动作。
第一步,先把任务说清楚,不要只说风格。
“帮我做一张高级感海报”这种说法几乎没有足够信息。更有效的描述应该包括:这张图给谁看、用在什么场景、主体是什么、是否包含文字、横版还是竖版、希望照片感还是插画感、最终想传达什么情绪和重点。
第二步,把不能出错的内容单独写清楚。
标题、副标题、比例、颜色范围、是否允许出现 logo、水印是否允许、人物朝向、信息位置,这些都属于硬约束。它们写得越明确,返工概率越低。
第三步,把生成看成一个迭代过程。
多数情况下,第一轮的目标只是先把方向做对,不必指望一条超长提示词一次完成所有事情。更稳妥的办法是先拿到一版底稿,再逐轮修改,例如调整标题字距、减弱背景噪点、压缩人物比例、给排版腾出空间等。
第四步,信息图、品牌图和文字图尽量用更具体的描述。
这类图的关键在于信息组织是否准确。描述越朴实、越具体,输出往往越稳。过于文艺的表达更适合氛围图、情绪图,对海报、课程图、菜单、路线图、知识卡片和论文配图帮助有限。
为什么我要专门介绍这个模型
我想专门写这个模型,一个很现实的原因是:它确实让很多过去很费劲的制图任务变得轻松了不少。尤其是在论文插图、科研框架图、方法图、项目海报这类场景里,过去我们往往要写很长很细的提示词,甚至一条提示词就接近一个小型说明书,才有机会把版式、层级和工程表达说清楚。
当前的模型相比于上一版的 ChatGPT 图像模型,以及前一版顶流模型 Banana 2,一个很明显的变化是:很多时候不需要再给出特别复杂的提示词,也能生成质量较高、结构较完整的图片。比如我要生成一个用于论文的框架图描述,以前需要的提示词如下:
1 | |
更新后只需要:
1 | |
这段对比很能说明问题。过去,要想让模型把学术风格、版式关系、工程逻辑和公式位置都理解到位,提示词往往要写得非常细,甚至要替模型提前把整张图的结构设计一遍。现在,很多任务仍然需要清楚表达,但不再需要把每一个细节都展开到这种程度。任务目标、核心结构和关键约束说清楚以后,模型通常就能给出一个可用的起点。
但这里同样要强调一点:提示词变短以后,人的工作依然重要。现在省下来的,主要是把想法翻译成机械描述的成本;对内容本身的判断仍然要由人来完成。图该怎么组织、哪几个模块要突出、公式要不要放进去、工程图和数据图如何平衡,这些都要靠人来决定。AI 可以帮你把草图迅速变成初稿,但初稿是否可靠、是否符合论文表达、是否适合投稿或展示,最后还是需要人来把关。
四、十个常见示例:大家最容易立刻用起来的玩法
下面这十个例子,提示词是我结合我的研究方向简单梳理的中文版本。我觉得对土木方向使用者来说,这些案例最重要的价值,在于它们能直接服务论文写作、项目汇报、科普传播和团队展示。
示例 1:论文总体框架图(Framework Diagram)
适用场景:SCI/中文核心论文、开题答辩、项目申报书、研究路线展示。
示例提示词:请绘制一张顶刊风格的科研框架图,主题为“Monitoring-driven stage-wise coupled response prediction and sequential model updating for deep excavation engineering”。整体采用白色背景、蓝灰色学术配色、矢量风格。图中包含 5 个模块,并用箭头串联:1)多源监测数据采集(位移、支撑轴力、地下水位、地表沉降);2)数据预处理与异常识别;3)机理模型与数据驱动模型耦合预测;4)参数反演与序贯更新;5)风险预警与决策支持。要求结构清晰、布局平衡、文字简洁专业、适合论文插图。
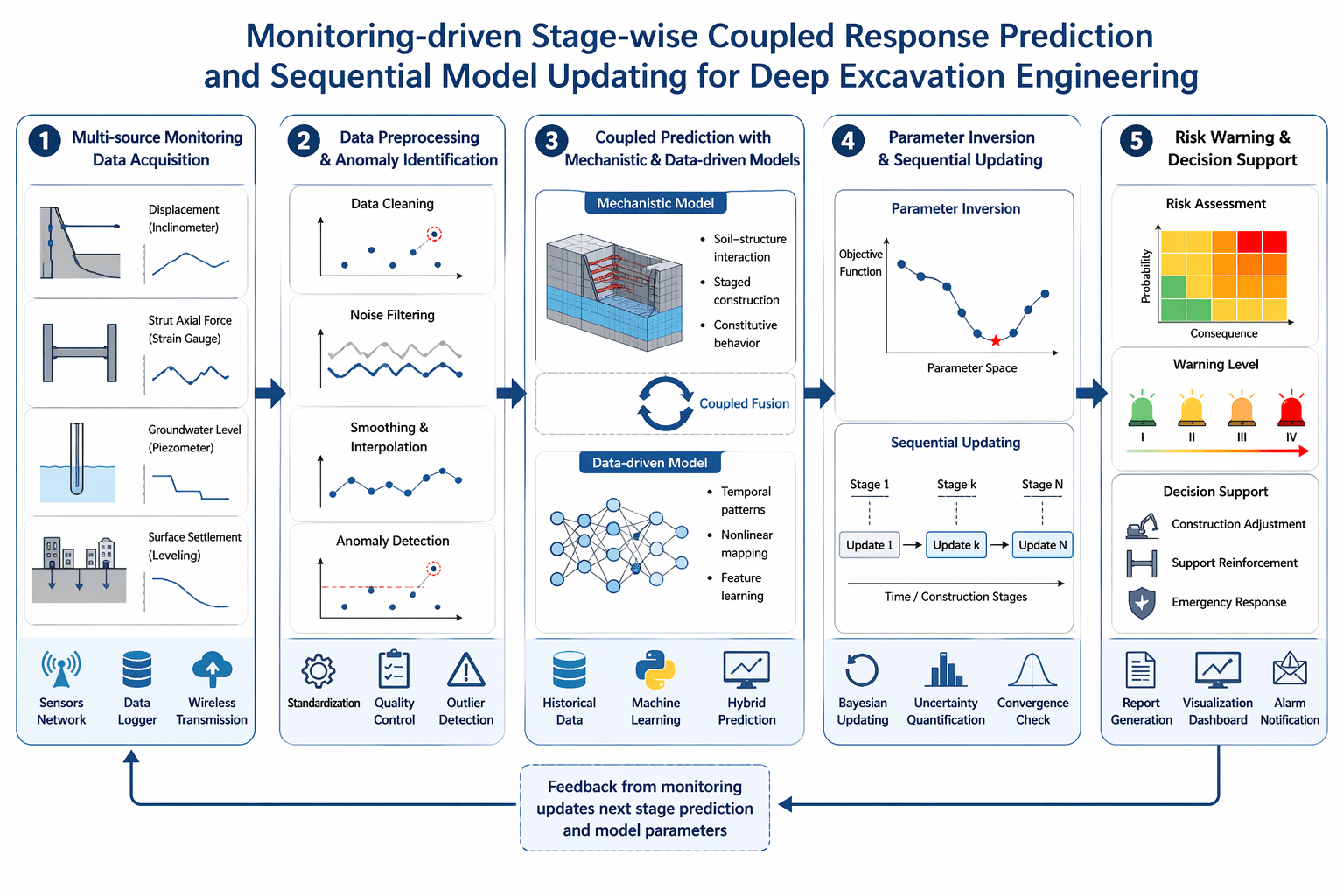
预期效果 / 使用价值:这类图非常适合土木科研人。以前很多人要用 PPT、Visio 或 draw.io 一点点拖,现在可以先让模型出一个高质量底稿,再做精修。
示例 2:基坑工程分阶段开挖示意图
适用场景:岩土工程论文、汇报 PPT、施工组织可视化、教学课件。
示例提示词:绘制一张深基坑工程分阶段开挖与支护示意图,采用学术论文插图风格,白色背景。图中表现地下连续墙、冠梁、三道水平支撑、坑底土体、周边地表、建筑物和监测点。用 Stage 1、Stage 2、Stage 3、Stage 4 表示各阶段开挖深度和支撑安装过程,并用不同颜色区分当前开挖土层。整体要求干净、准确、工程感强,适合论文发表。
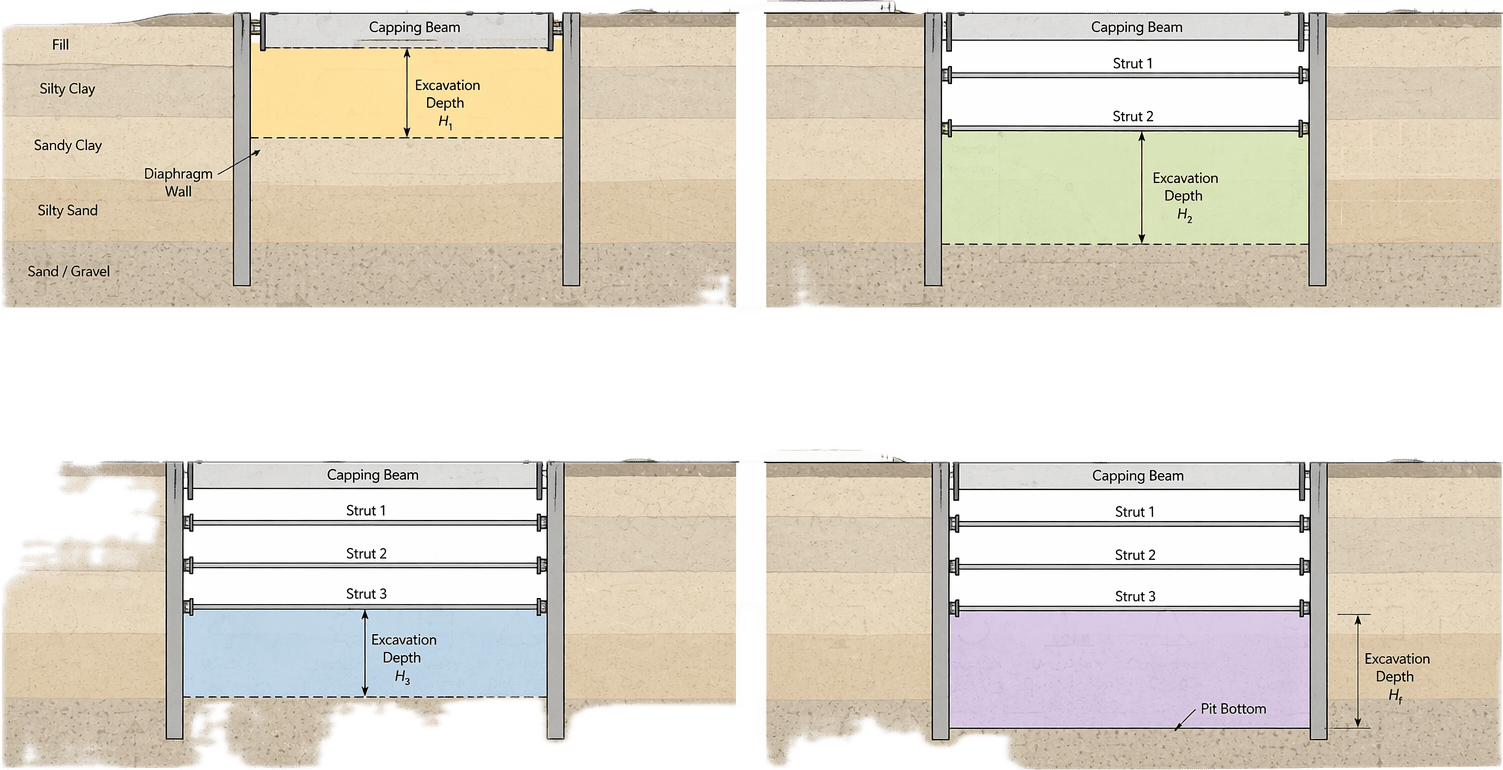
预期效果 / 使用价值:这是岩土方向最常用的配图之一。它很适合替代生硬的 CAD 截图,让论文插图更统一、更现代。
示例 3:监测数据到预警决策的闭环流程图
适用场景:智能建造、智慧工地、监测预警系统研究、项目汇报。
示例提示词:设计一张“基坑监测—分析—预警—决策”的闭环流程图,风格现代、学术化、适合项目汇报。流程包括:监测设备采集、人工巡检、数据上传、质量控制、异常检测、模型分析、风险评估、预警发布、专家会商、施工调整。整体为横向流程布局,图标简洁统一,配色以蓝色和橙色为主,白色背景。
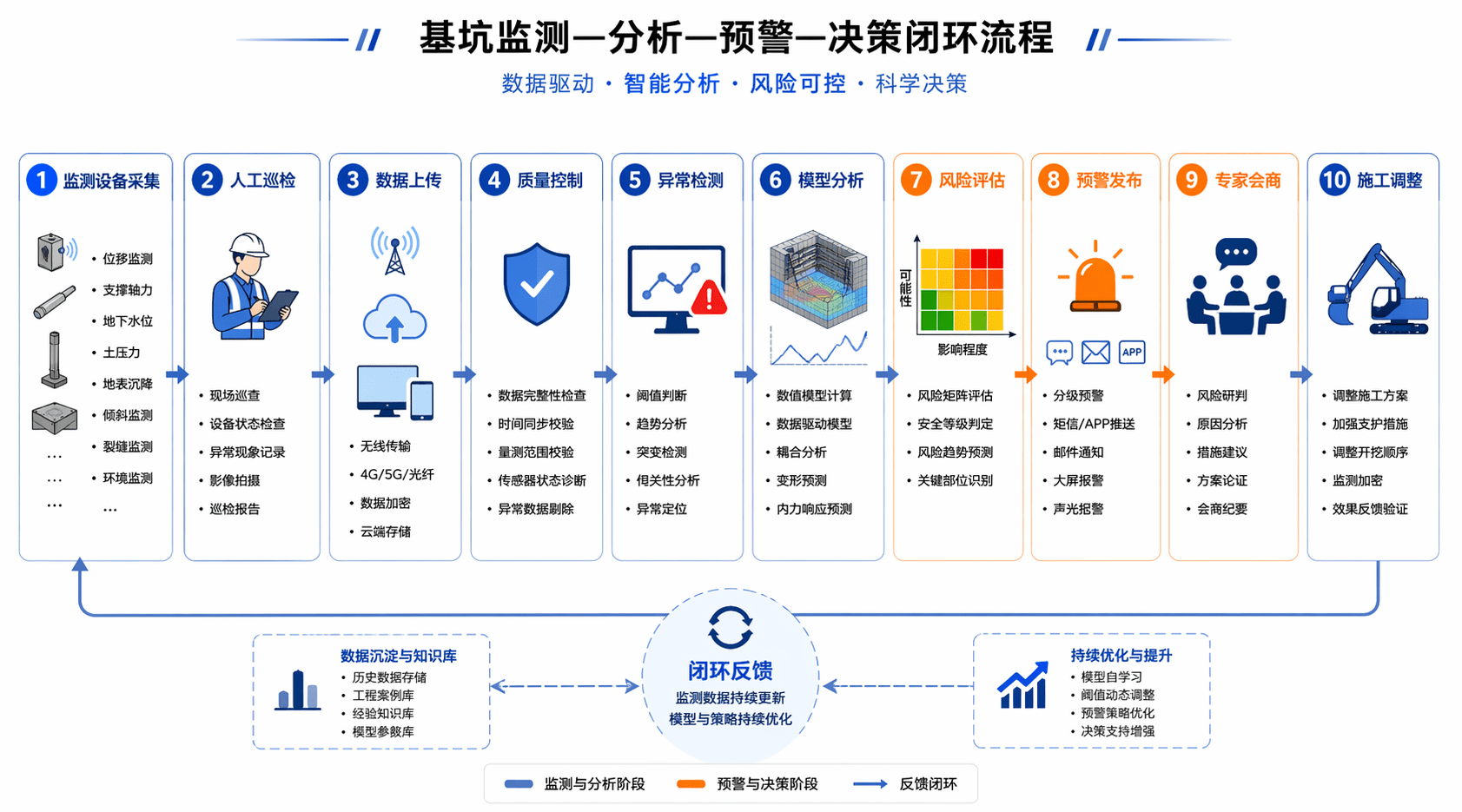
预期效果 / 使用价值:这类图特别适合智能建造方向,不仅能放论文里,也很适合做项目汇报首页图。
示例 4:隧道裂缝智能识别方法图
适用场景:计算机视觉与土木工程交叉研究、论文方法图、算法说明。
示例提示词:绘制一张隧道衬砌裂缝智能识别的科研方法图,分为四个部分:1)原始图像采集;2)图像增强与预处理(CLAHE、Gamma 校正、小波增强);3)深度学习分割模型识别裂缝;4)裂缝长度、宽度与分布统计分析。要求整体为顶刊风格信息图,模块分明,带示意图标和箭头连接,白色背景,颜色简洁统一,适合放在论文中。
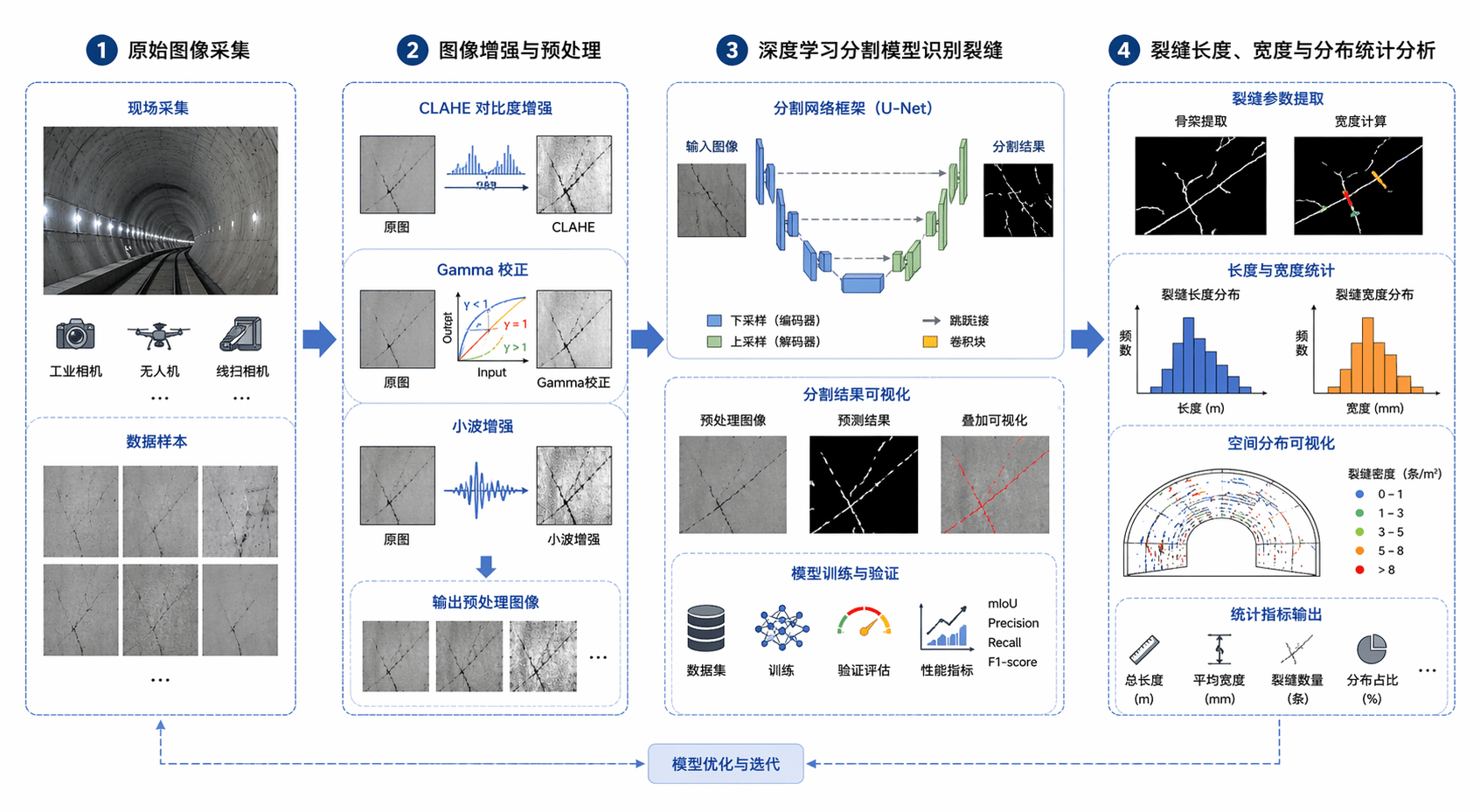
预期效果 / 使用价值:这种图能把“算法流程”说清楚,尤其适合做论文中的 Figure 1 或方法总图。
示例 5:BIM + GIS + 监测数据融合概念图
适用场景:数字孪生、智能建造、基础设施运维、科研申报书。
示例提示词:生成一张“BIM-GIS-监测数据融合驱动的土木工程数字孪生平台”概念图。图中从左到右依次包括:现场工程实体、传感器网络、BIM 模型、GIS 场景、数据中台、分析预测引擎和决策驾驶舱。整体采用三维轻科技风格与二维信息图结合,色调为蓝色、青色和灰色,白色背景,适合学术汇报与项目申报展示。

预期效果 / 使用价值:这类图特别适合写“平台型研究”“系统型研究”,很多老师看一眼就能快速理解你的研究定位。
示例 6:论文图形摘要(Graphical Abstract)
适用场景:SCI 投稿、期刊图形摘要、研究成果展示。
示例提示词:设计一张图形摘要,主题为“Stage-wise deformation prediction and safety warning for deep excavation based on monitoring data and hybrid modeling”。图中从左到右展示:工程场景、监测数据输入、模型耦合分析、变形预测结果、风险预警输出。要求极简学术风、视觉清晰、信息密度适中、适合 SCI 期刊 graphical abstract,背景纯白,文字精炼。
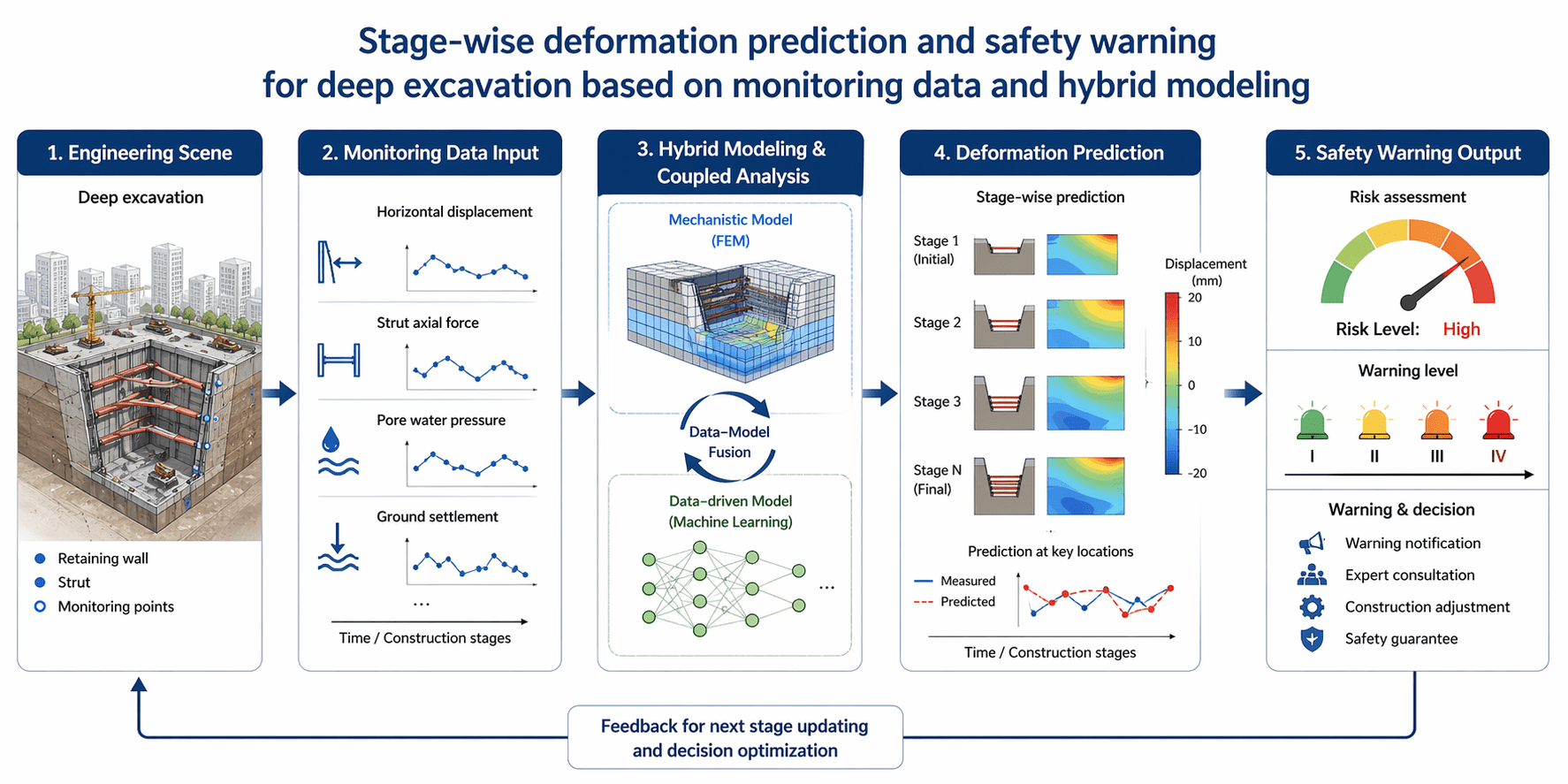
预期效果 / 使用价值:很多论文最难处理的内容,往往集中在图形摘要和封面式摘要上。这类任务很适合让模型先把版式和结构搭出来,再由作者自己细化。
示例 7:学术汇报 PPT 封面图
适用场景:研究生答辩、组会汇报、课题汇报、学术讲座。
示例提示词:制作一张学术汇报 PPT 封面图,主题为“面向深基坑工程的监测驱动安全预测预警方法研究”。画面包含简洁的基坑工程线稿、监测曲线、数据流、城市建筑轮廓等元素,整体风格高端、简洁、学术,适合 16:9 横版 PPT 首页,背景以白色和浅灰为主,带蓝色点缀,并留出标题与作者信息位置。

预期效果 / 使用价值:很多学生的 PPT 首页比较普通,这类图可以显著提升整体观感,而且不会像纯艺术图那样显得发飘。
示例 8:工程项目宣传海报
适用场景:课题组宣传、项目路演、成果墙、公众号推文配图。
示例提示词:设计一张现代感科研项目宣传海报,主题为“岩土工程智能安全预测预警平台”。画面中包含基坑工程、监测传感器、数据大屏、三维模型、预警图标和科研团队元素。整体风格专业、科技感强、适合高校实验室和项目成果展示。版式清晰,保留标题区、亮点区和底部介绍区。

预期效果 / 使用价值:这类图很适合公众号头图、展板和实验室成果墙,兼具传播和展示价值。
示例 9:试验装置与研究方案示意图
适用场景:试验研究论文、实验方案说明、专利交底书配图。
示例提示词:绘制一张科研试验装置与研究方案示意图,主题为“模型试验中基坑支护结构受力与变形监测系统”。图中包括模型箱、土体、支护结构、支撑体系、位移计、应变计、数据采集器和注释箭头。风格为清晰的工程矢量插图,白色背景,标注规范,适合用于论文和专利说明书。
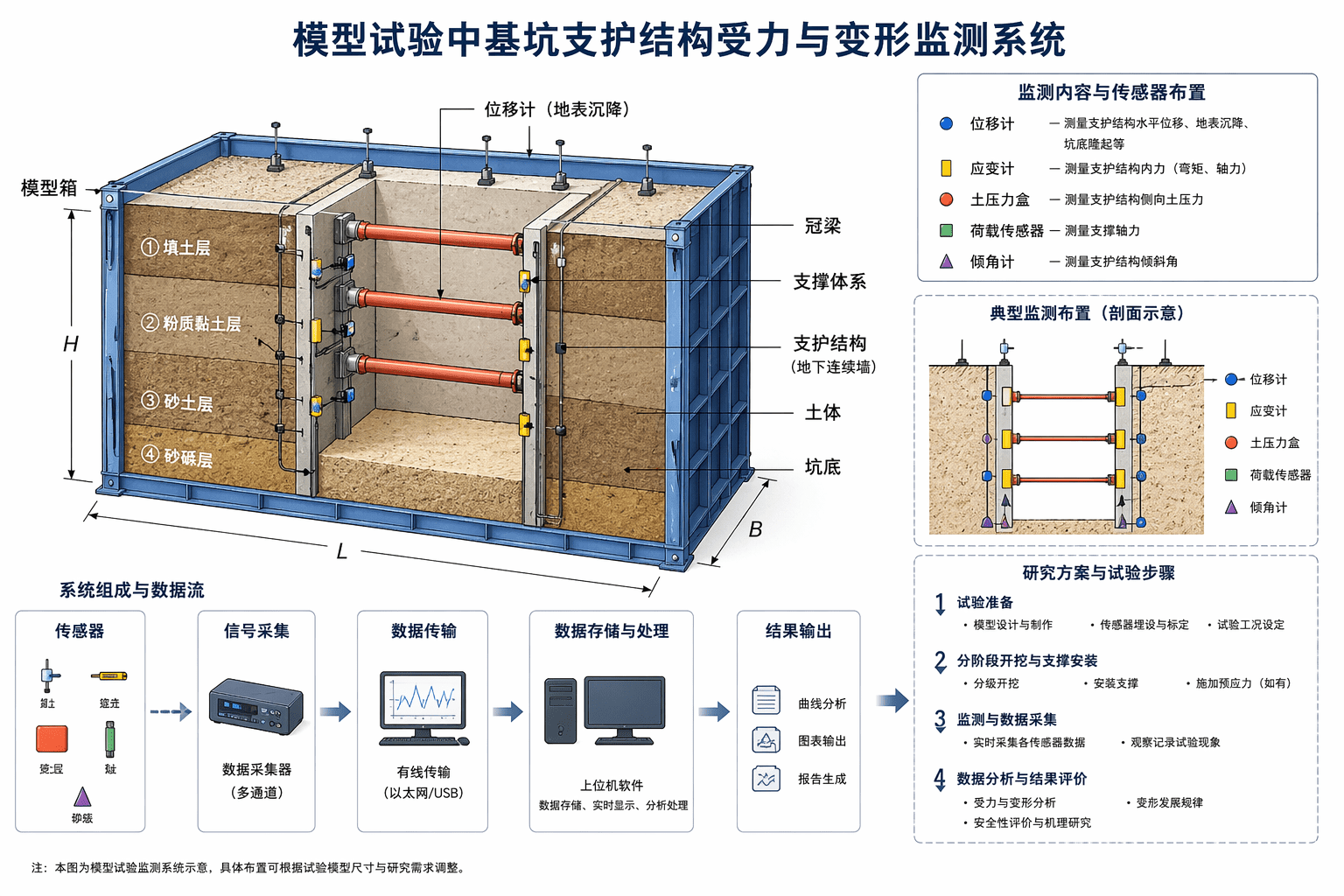
预期效果 / 使用价值:很多时候,作者需要的是一张能让审稿人一眼看懂试验布置的图。
示例 10:工程科普长图 / 公众号头图
适用场景:学术传播、公众号文章、科研成果科普、招生宣传。
示例提示词:设计一张面向大众传播的公众号头图,主题为“为什么基坑监测如此重要?”。画面包含城市建筑、基坑剖面、监测点、报警符号和数据曲线,用简洁现代的信息图风格表达“监测—分析—预警—安全”的逻辑。整体为横版,视觉清晰,标题突出,适合公众号推文首图。
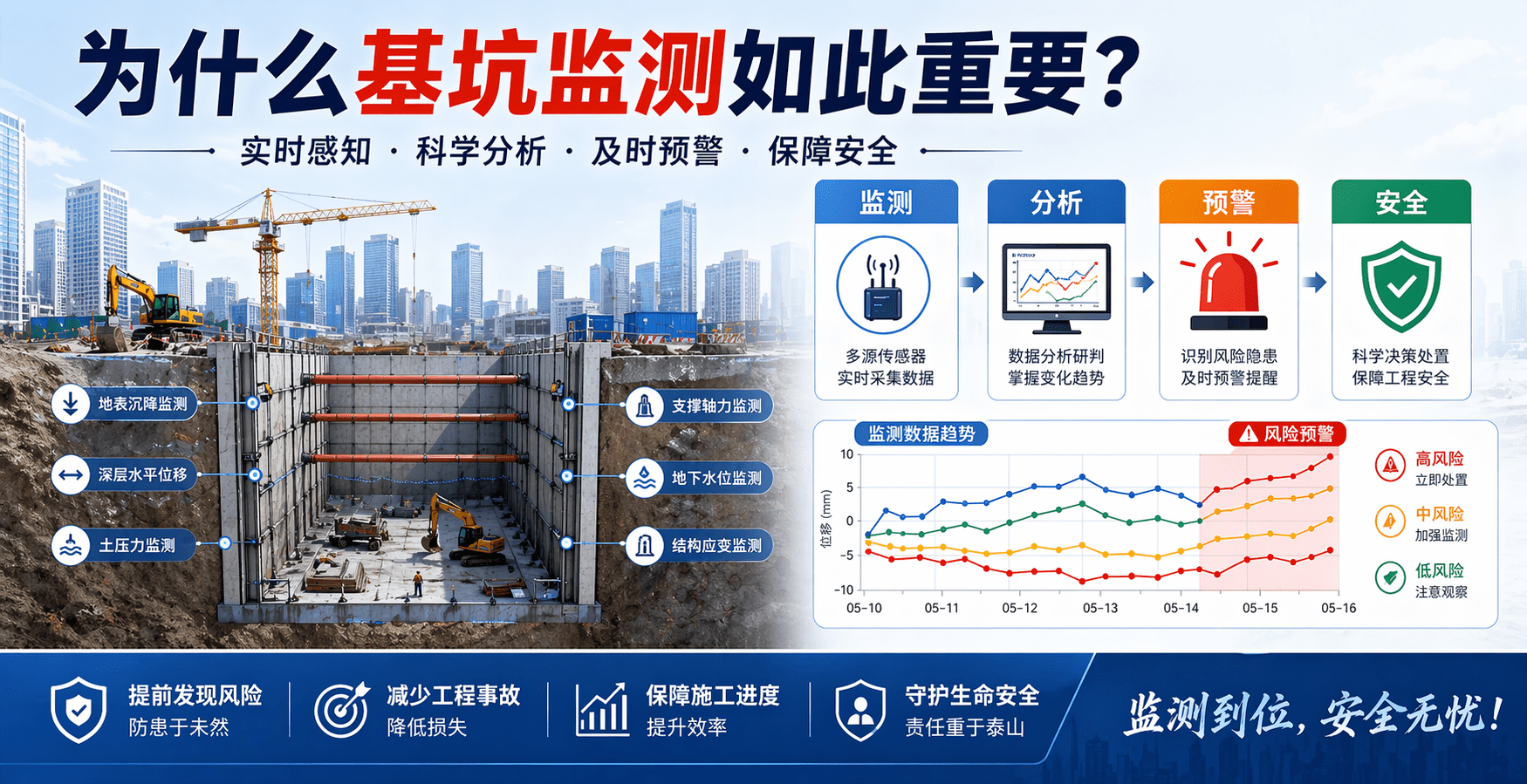
预期效果 / 使用价值:如果你要运营公众号、展示团队成果或者做招生宣传,这类图非常好用。
五、给大家的三条实话
第一,ChatGPT Image 2 并不会自动替你完成审美判断。
模型可以帮你出图,但什么图适合你的文章、品牌、研究和传播场景,仍然需要你自己来判断。它降低的是制图和表达的门槛,不会顺手把判断力也一起补上。
第二,AI 能提高执行效率,但不能代替人去产生想法。
你可以用它把脑中的方案快速变成可见的图,把原本需要几小时甚至几天的制图过程压缩到更短时间,也可以用它快速尝试不同版式和表达方向。但你到底想表达什么、哪些信息最重要、要不要保留某些模块、最终图像服务于哪种研究或传播目的,这些仍然要靠人来决定。真正的想法、观点和判断,不能外包给工具。
第三,效果上限始终取决于你的表达清晰度。
谁能把场景、主体、约束、用途、构图和文字需求讲得更清楚,谁就更容易把模型变成生产力。OpenAI 的提示词指南反复强调的,其实也就是这一点:结构化、具体化、可迭代,比模糊、玄学式的提示更有用。
结语
如果回头看这几年的 AI 绘图发展,会发现它已经从单纯展示“机器也能画图”,逐渐走向参与真实视觉工作的阶段。ChatGPT Image 2 的价值,就体现在它开始能够进入更完整的创作链条:理解需求、生成初稿、接受修改、处理复杂文本、组织多层信息,并尽量输出一张可继续使用的图。
当然,它依然有局限。裁切、复杂关系、精确图表、多语言小字、编辑准确性等方面,仍然存在不稳定的地方。公开资料里也承认了这一点。所以,使用它时仍然需要保持基本判断:该不该信、能不能直接用、哪些地方必须人工复核、哪些内容必须重新绘制。
但对于大多数普通创作者、科研人员和内容生产者来说,它已经足够成为一个很实用的工具。它能帮我们更快把想法做出来,帮我们更低成本地试错,也能帮我们把过去难以完成的一些视觉表达推进到可修改、可展示、可发布的阶段。
更值得重视的是,更多人终于有机会把自己的想法更直接地表达出来。前提始终没有变:想法来自人,工具负责帮助实现。只要这一点不被弄反,AI 图像工具就会越来越有用。
参考链接
- https://help.openai.com/en/articles/6825453-chatgpt-release-notes?os=os “https://help.openai.com/en/articles/6825453-chatgpt-release-notes?os=os“ ↩
- https://developers.openai.com/api/docs/guides/image-generation “https://developers.openai.com/api/docs/guides/image-generation“ ↩
- https://openai.com/vi-VN/index/introducing-4o-image-generation/ “https://openai.com/vi-VN/index/introducing-4o-image-generation/“ ↩
- https://deploymentsafety.openai.com/chatgpt-images-2-0 “https://deploymentsafety.openai.com/chatgpt-images-2-0“ ↩
- https://openai.com/nb-NO/index/introducing-chatgpt-images-2-0/ “https://openai.com/nb-NO/index/introducing-chatgpt-images-2-0/“ ↩
- https://developers.openai.com/api/docs/models/all “https://developers.openai.com/api/docs/models/all“ ↩
- https://developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide “https://developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide“ ↩